
들어가며
Truth is not determined by a majority vote - Pope Benedict XVI
진실은 다수결로 결정되지 않는다는 말이 있죠.
그러나 DDIA에서 마틴 클레프만이 말했듯이 분산 시스템의 합의 Consensus는 이야기가 다른데요.

노드 간 선거에 의해 quorum 정족수 이상의 득표를 했을 때, 시스템의 어떠한 문제에 대해 합의하는 Raft Consensus Algorithm 뗏목 합의 알고리즘 에 적용되는 이야기입니다. 물론 이 외에도 많은 합의 알고리즘이 있습니다.
Raft Consensus Algorithm에 대해서 잘 정리한 블로그가 있네요. Raft에 대한 자세한 설명은 링크로 갈음하겠습니다 :)
모든 노드가 어떤 문제에 동의하는 합의는 분산 시스템에서 가장 중요한 개념 중 하나입니다.
합의의 대표적인 케이스가 바로 단일 리더 리플리케이션에서의 Failover입니다.
구현체에 따라 프라이머리, 또는 마스터라 불리기도 하는 이 리더가 죽어서(다운되어) 합의를 통해 새로운 리더를 선출하는것이죠.
물론 꼭 리더가 다운되는 케이스 뿐만 아니라 일시적인 네트워크 중단, 혹은 프로세스의 일시적 중단(예를 들어, GC로 stop-the-world)으로 응답하지 않는 경우에도 발생할 수 있습니다.
결국, 통신에 의존하게 될 수 밖에 없으니까요.
합의에 의한 Failover 는 HA를 보장하기 위한 수단으로서, 분산 시스템을 다루는 엔지니어라면 익숙한 개념이겠습니다.
HA를 제공하기 위한 Failover에 Raft 알고리즘을 적용하는 대표적인 NoSQL 데이터베이스가 있죠. MongoDB와 Redis입니다.
MongoDB는 Replicaset, Redis는 Sentinel과 sharded cluster를 통해 데이터베이스 자체적으로 Automatic Failover를 지원하는데요.
모두 Raft 알고리즘을 적용하여 노드간 정족수 합의를 이뤄냅니다.
그런데 MongoDB Replica set과 Redis Sentinel의 합의에는 조금 차이가 있어요.MongoDB Replica set은 quorum을 조정하지 못해 반드시 노드의 과반 이상의 합의가 이뤄져야 하는 반면, Sentinel은 quorum을 조절할 수 있습니다.
이를 통해 Sentinel은 과반이 되지 않더라도 Automatic Failover가 가능하다는 이야기입니다.
그런데, 항상 그럴까요? 장애 상황 시뮬레이션을 통해 확인해보겠습니다.
Hands-on 시뮬레이션
시뮬레이션을 진행할 Redis Replication과 Sentinel의 형상을 먼저 보겠습니다.
Redis Replication

일반적인 MSS 구조의 Redis Replication입니다.Redis 1이 현재 마스터(리더)로 위치해있으며, Redis 2, 3 은 슬레이브(팔로워)로 위치해 있습니다.
INFO Replication
레플리케이션 정보를 확인합니다.
MASTER
127.0.0.1:6379> INFO REPLICATION
# Replication
role:master
connected_slaves:2
slave0:ip=<SLAVE 0 IP>,port=6379,state=online,offset=144685,lag=1
slave1:ip=<SLAVE 1 IP>,port=6379,state=online,offset=145133,lag=0
master_failover_state:no-failover
master_replid:7068ca3784b79d7030069df9d08a4a6d28deff40
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:145133
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:207618048
repl_backlog_first_byte_offset:1
repl_backlog_histlen:145133connected_slaves: 2 로 보이는 것과 같이 현재 2개의 슬레이브와 연결되어 있습니다.
SLAVE
127.0.0.1:6379> INFO REPLICATION
# Replication
role:slave
master_host:<MASTER-HOST>
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:155955
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:7068ca3784b79d7030069df9d08a4a6d28deff40
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:155955
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:207618048
repl_backlog_first_byte_offset:1
repl_backlog_histlen:155955master_link_status: up
슬레이브도 마스터를 정상적으로 팔로우하고 있습니다.
Redis Sentinel
다음은 Redis replication을 observe 하는 Redis Sentinel 구성입니다.
sentinel.conf
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
#
# Tells Sentinel to monitor this master, and to consider it in O_DOWN
# (Objectively Down) state only if at least <quorum> sentinels agree.
#
...
# Note: master name should not include special characters or spaces.
# The valid charset is A-z 0-9 and the three characters ".-_".
sentinel monitor sentinel_group <마스터-노드-IP> 6379 1이 문서의 앞에서 Redis Sentinel은 quorum을 조정할 수 있다고 말했습니다.
Sentinel의 구성 파일 sentinel.conf에서 quorum 1로 조정하고, 프로세스로 올리겠습니다.
127.0.0.1:26379> INFO sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=sentinel_group,status=ok,address=<YOUR-MASTER-IP>:6379,slaves=2,sentinels=3redis-cli 를 통해 센티넬에 접근하고, 센티넬 정보를 확인합니다.
레플리케이션을 observe 하고 있네요.
우리가 진행할 Sentinel과 Redis Replication의 형상은 다음과 같습니다.

센티넬과 레디스가 반드시 동일 서버에 구성되어야 할 필요는 없습니다. 의존성도 없구요.
레디스 공식 문서에서는 모든 프로세스가 서로 다른 장비에 구성되는 것을 권장합니다만, Sentinel은 Redis를 observe 하는 것 외에 다른 역할을 수행하지 않아 많은 리소스를 필요로 하지 않기에, 실제 구성시에는 Redis server 와 함께 구성하기도 합니다.
MongoDB Replicaset 과 유사한 구조인거죠(물론 redis와 sentinel은 별도의 프로세스입니다만). Sentinel은 coordinator 역할입니다.

그리고 우리는 앞서quorum = 1로 설정했었죠. 장애가 발생하기 전, Redis Replication과 sentinel group의 형상입니다.
지금부터는 Redis와 Sentinel이 함께 구성된 장비를 각각 노드 1, 노드 2, 노드 3이라고 하겠습니다.
장애상황 발생
장애 상황이 발생했습니다.
여러 상황이 가능하겠지만, 재해로 인해 AZ 레벨의 데이터 센터가 무너졌다고 해볼까요.
2번 노드(S), 그 다음 1번 노드(M)가 순서대로 다운되는 상황을 가정하겠습니다.
2번 노드(S) 다운
2번 노드가 다운됩니다.2번 노드의 레디스는 슬레이브로, 다운되어도 failover가 일어나지 않습니다.
root@<노드 2>:/redis# systemctl stop sentinel.service
root@<노드 2>:/redis# systemctl status sentinel.service
● sentinel.service - Redis in-memory data structure store
Loaded: loaded (/etc/systemd/system/sentinel.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Sun 2023-06-25 15:14:41 KST; 4min 42s ago
...
Jun 24 21:14:02 <노드 2> systemd[1]: Started Redis in-memory data structure store.
Jun 25 15:00:17 <노드 2> systemd[1]: Stopping Redis in-memory data structure store...
Jun 25 15:00:17 <노드 2> systemd[1]: sentinel.service: Succeeded.
Jun 25 15:00:17 <노드 2> systemd[1]: Stopped Redis in-memory data structure store.Sentinel이 다운됩니다.
root@<노드 2>:/redis# systemctl stop redis.service
root@<노드 2>:/redis# systemctl status redis.service
● redis.service - Redis in-memory data structure store
Loaded: loaded (/etc/systemd/system/redis.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Sun 2023-06-25 15:14:54 KST; 4min 30s ago
...
Jun 24 20:58:32 <노드 2> systemd[1]: Started Redis in-memory data structure store.
Jun 25 15:00:41 <노드 2> systemd[1]: Stopping Redis in-memory data structure store...
Jun 25 15:00:41 <노드 2> redis-cli[32013]: NOPERM this user has no permissions to run the 'shutdown' command or its subcommand
Jun 25 15:00:41 <노드 2> systemd[1]: redis.service: Succeeded.
Jun 25 15:00:41 <노드 2> systemd[1]: Stopped Redis in-memory data structure store.Redis가 다운됩니다.
127.0.0.1:6379> INFO REPLICATION
# Replication
role:master
connected_slaves:1
slave0:ip=<노드 1>,port=6379,state=online,offset=14249741,lag=0
master_failover_state:no-failover
master_replid:7068ca3784b79d7030069df9d08a4a6d28deff40
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14249741
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:207618048
repl_backlog_first_byte_offset:1
repl_backlog_histlen:14249741Replication Master인 Redis 1 에서 확인하니, connected_slaves:1 로서 연결된 슬레이브 개수가 줄어든 것을 확인할 수 있습니다.
28802:X 25 Jun 2023 15:00:47.107 # +sdown sentinel c365b2a2368389ef7c27ab2e2b45517b8ab3f9b7 <노드 2> 26379 @ sentinel_group <노드 1> 6379
28802:X 25 Jun 2023 15:00:56.043 * +fix-slave-config slave <노드 3>:6379 <노드 3> 6379 @ sentinel_group <노드 1> 6379
28802:X 25 Jun 2023 15:01:06.075 * +fix-slave-config slave <노드 3>:6379 <노드 3> 6379 @ sentinel_group <노드 2> 6379
28802:X 25 Jun 2023 15:01:11.779 # +sdown slave <노드 2>:6379 <노드 2> 6379 @ sentinel_group <노드 1> 6379노드 1의 sentinel.log를 확인하니, 노드 2의 redis와 sentinel을 모두 sdown 주관적 down 처리한 것이 확인되었습니다.
2번 노드가 다운된 현재, Redis Replication 형상은 다음과 같습니다.

1번 노드(M) 다운
Redis Replication의 master가 위치하는 1번 노드가 다운됩니다.sentinel quorum을 1로 설정하였기 때문에, 1번 노드가 다운되어도 3번 노드의 sentinel과 redis가 여전히 남아 있어 automatic failover를 기대해볼 수 있습니다.
root@<노드 1>:/redis# systemctl status sentinel.service
● sentinel.service - Redis in-memory data structure store
Loaded: loaded (/etc/systemd/system/sentinel.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Sun 2023-06-25 15:14:41 KST; 4min 42s ago
...
Jun 24 21:14:02 <노드 1> systemd[1]: Started Redis in-memory data structure store.
Jun 25 15:14:41 <노드 1> systemd[1]: Stopping Redis in-memory data structure store...
Jun 25 15:14:41 <노드 1> systemd[1]: sentinel_26379.service: Succeeded.
Jun 25 15:14:41 <노드 1> systemd[1]: Stopped Redis in-memory data structure store.Sentinel이 다운됩니다.
root@<노드 1>:/redis# systemctl status redis.service
● redis.service - Redis in-memory data structure store
Loaded: loaded (/etc/systemd/system/redis.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Sun 2023-06-25 15:14:54 KST; 4min 30s ago
...
Jun 24 20:58:32 <노드 1> systemd[1]: Started Redis in-memory data structure store.
Jun 25 15:14:54 <노드 1> systemd[1]: Stopping Redis in-memory data structure store...
Jun 25 15:14:54 <노드 1> redis-cli[31867]: NOPERM this user has no permissions to run the 'shut>
Jun 25 15:14:54 <노드 1> systemd[1]: redis.service: Succeeded.
Jun 25 15:14:54 <노드 1> systemd[1]: Stopped Redis in-memory data structure store.Redis가 다운됩니다.

Redis 3이 master 승격 되었을 것으로 기대되는데요.
failover 여부 확인
127.0.0.1:6379> INFO REPLICATION
# Replication
role:slave
master_host:<노드 1>
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:14276857
master_link_down_since_seconds:116
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:7068ca3784b79d7030069df9d08a4a6d28deff40
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14276857
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:207618048
repl_backlog_first_byte_offset:813
repl_backlog_histlen:14276045그러나 Redis 3을 확인하니, 여전히 slave로 남아 있습니다.
127.0.0.1:26379> INFO SENTINEL
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=sentinel_group,status=odown,address=<노드 1>:6379,slaves=2,sentinels=3Sentinel 3를 확인하니, 분명 master인 Redis 1를 odown으로 인식하고 있는데요.
원인 파악을 위해 Redis 3의 로그를 확인해 보겠습니다.
28426:S 25 Jun 2023 15:17:26.076 # Error condition on socket for SYNC: Connection refused
28426:S 25 Jun 2023 15:17:27.079 * Connecting to MASTER <노드 1>:6379
28426:S 25 Jun 2023 15:17:27.080 * MASTER <-> REPLICA sync started
28426:S 25 Jun 2023 15:17:27.080 # Error condition on socket for SYNC: Connection refused
28426:S 25 Jun 2023 15:17:28.083 * Connecting to MASTER <노드 1>:6379
28426:S 25 Jun 2023 15:17:28.084 * MASTER <-> REPLICA sync started
28426:S 25 Jun 2023 15:17:28.085 # Error condition on socket for SYNC: Connection refused
28426:S 25 Jun 2023 15:17:29.088 * Connecting to MASTER <노드 1>:6379
28426:S 25 Jun 2023 15:17:29.089 * MASTER <-> REPLICA sync started
28426:S 25 Jun 2023 15:17:29.089 # Error condition on socket for SYNC: Connection refusedredis.log
slave인 Redis 3은 계속해서 master와 연결을 시도하고 있네요.
Sentinel 3의 로그를 확인해 보겠습니다.
28802:X 25 Jun 2023 15:15:11.634 # +sdown sentinel 7021e8b17a306e0f31edb9b098c842c4e303dd05 <노드 1> 26379 @ sentinel_group <노드 1> 6379
28802:X 25 Jun 2023 15:15:24.981 # +sdown master sentinel_group <노드 3> 6379
28802:X 25 Jun 2023 15:15:24.981 # +odown master sentinel_group <노드 3> 6379 #quorum 1/1
28802:X 25 Jun 2023 15:15:24.981 # +new-epoch 1
28802:X 25 Jun 2023 15:15:24.981 # +try-failover master sentinel_group <노드 3> 6379
28802:X 25 Jun 2023 15:15:24.990 # +vote-for-leader b1142c4bda42264da55c8c3487b1d97a2eca3c67 1
28802:X 25 Jun 2023 15:15:35.809 # -failover-abort-not-elected master sentinel_group <노드 3> 6379
28802:X 25 Jun 2023 15:15:35.892 # Next failover delay: I will not start a failover before Sun Jun 25 15:21:25 2023sentinel.log
센티넬 3은 노드 1에 위치한 Redis 1에 문제가 생겼음을 인지하고, sdown으로 판단, +vote-for-leader에 대해 quorum 1/1 조건을 만족하게 되었습니다.
이제 이 문제는 odown 이 되었는데요.
28802:X 25 Jun 2023 15:15:35.809 # -failover-abort-not-elected master sentinel_group <노드 3> 6379
28802:X 25 Jun 2023 15:15:35.892 # Next failover delay: I will not start a failover before Sun Jun 25 15:21:25 2023
그럼에도 automatic failover는 실패했습니다. 이유가 뭘까요 ?

원인 분석
Redis Sentinel 공식 문서에서 그 힌트를 찾아볼 수 있습니다.
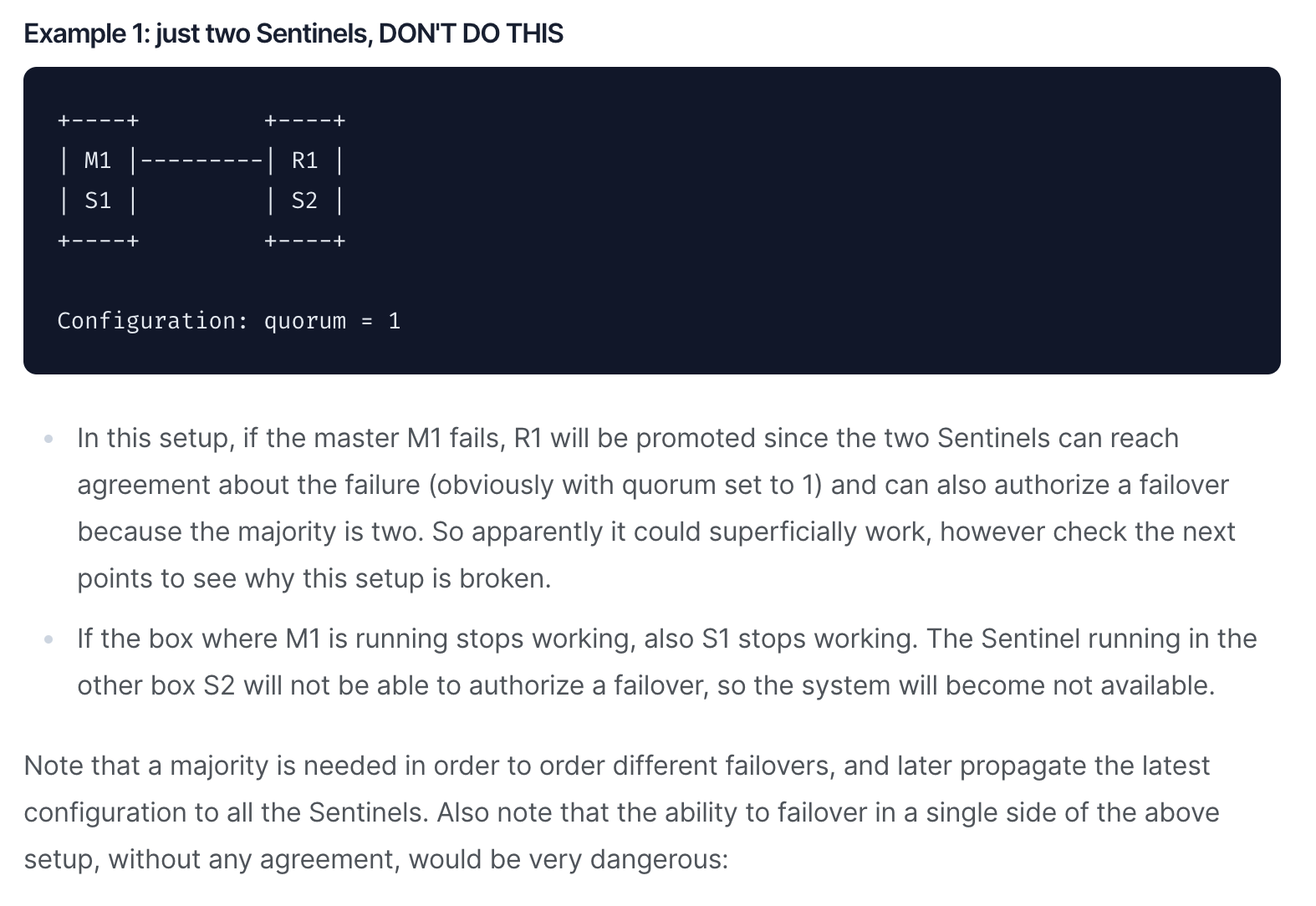
위 문단을 보면, 마스터 M1이 장애가 발생했을 때,
quorum설정에 따라 2개 이상의Sentinel이failover합의에 도달할 수 있다.
…서로 다른
failover를 주문하고 나중에 모든Sentinel에 최신 구성을 전파하려면 과반수가 필요하다. 또한 위 설정에서 한 쪽에서 동의 없이 페일오버할 수 있는 기능은 매우 위험하다.
라는 이야기가 나옵니다. quorum 조건을 만족하여 odown이 되어도, 결국 sentinel 과반의 동의가 필요하다는 말로 추측이 됩니다.
28802:X 25 Jun 2023 17:03:35.470 # +new-epoch 19
28802:X 25 Jun 2023 17:03:35.471 # +try-failover master sentinel_group 10.182.102.105 6379
28802:X 25 Jun 2023 17:03:35.482 # +vote-for-leader b1142c4bda42264da55c8c3487b1d97a2eca3c67 19
28802:X 25 Jun 2023 17:03:46.047 # -failover-abort-not-elected master sentinel_group <노드 1> 6379
28802:X 25 Jun 2023 17:03:46.114 # Next failover delay: I will not start a failover before Sun Jun 25 17:09:36 2023sentinel.log 를 보면+new-epoch 라인부터 Next failover delay: ... 라인 까지, 센티넬이 Failover를 시도하며 떨어뜨린 로그입니다.
오픈 소스의 가장 큰 장점은, 말 그대로 오픈 소스라는 데 있지 않을까요.
GitHub redis repositry의 sentinel.c 코드 베이스를 확인하여 해당 로그를 떨어뜨린 상황을 추적해 보겠습니다.
sentinel.c 확인
/* This function checks if there are the conditions to start the failover,
* that is:
*
* 1) Master must be in ODOWN condition.
* 2) No failover already in progress.
* 3) No failover already attempted recently.
*
* We still don't know if we'll win the election so it is possible that we
* start the failover but that we'll not be able to act.
*
* Return non-zero if a failover was started. */
int sentinelStartFailoverIfNeeded(sentinelRedisInstance *master) {
/* We can't failover if the master is not in O_DOWN state. */
if (!(master->flags & SRI_O_DOWN)) return 0;
/* Failover already in progress? */
if (master->flags & SRI_FAILOVER_IN_PROGRESS) return 0;
/* Last failover attempt started too little time ago? */
if (mstime() - master->failover_start_time <
master->failover_timeout*2)
{
if (master->failover_delay_logged != master->failover_start_time) {
time_t clock = (master->failover_start_time +
master->failover_timeout*2) / 1000;
char ctimebuf[26];
ctime_r(&clock,ctimebuf);
ctimebuf[24] = '\0'; /* Remove newline. */
master->failover_delay_logged = master->failover_start_time;
serverLog(LL_NOTICE,
"Next failover delay: I will not start a failover before %s",
ctimebuf);
}
return 0;
}
sentinelStartFailover(master);
return 1;
}sentinelStartFailoverIfNeeded() 메서드를 통해 sentinel은 Failover 진행 여부를 확인합니다.
여기서 말하는 필요한 경우는,
sentinel master가SRI Sentinel Redis Instance를odown으로 인식하고(master->flags & SRI_O_DOWN)Failover가 진행되고 있지 않으며(master->flags & SRI_FAILOVER_IN_PROGRESS)- 마지막
Failover시도가 너무 직전에 일어나지 않은 경우
sentinelStartFailover() 하게 되겠습니다.
/* Setup the master state to start a failover. */
void sentinelStartFailover(sentinelRedisInstance *master) {
serverAssert(master->flags & SRI_MASTER);
master->failover_state = SENTINEL_FAILOVER_STATE_WAIT_START;
master->flags |= SRI_FAILOVER_IN_PROGRESS;
master->failover_epoch = ++sentinel.current_epoch;
sentinelEvent(LL_WARNING,"+new-epoch",master,"%llu",
(unsigned long long) sentinel.current_epoch);
sentinelEvent(LL_WARNING,"+try-failover",master,"%@");
master->failover_start_time = mstime()+rand()%SENTINEL_MAX_DESYNC;
master->failover_state_change_time = mstime();
}Sentinel이 Failover를 진행하는 sentinelStartFailover() 메서드 입니다.
odown을 인식한sentinel은failover_state를sentinel의 상태를Failover를 대기하는SENTINEL_FAILOVER_STATE_WAIT_START로 변경합니다.- 센티넬의 현재
epoch에 1을 더하여,failover_epoch로 기록합니다. - 이후 센티넬은 새로운
epoch와 함께Failover를 제안, 투표를 진행하며, - 이후
+try-failover이벤트는 다른 센티넬에 전파되어, 센티넬들이 전파된 이벤트를 합의한다면Failover가 이뤄지게 됩니다.
/* --------------- Failover state machine implementation ------------------- */
void sentinelFailoverWaitStart(sentinelRedisInstance *ri) {
char *leader;
int isleader;
/* Check if we are the leader for the failover epoch. */
leader = sentinelGetLeader(ri, ri->failover_epoch);
isleader = leader && strcasecmp(leader,sentinel.myid) == 0;
sdsfree(leader);
/* If I'm not the leader, and it is not a forced failover via
* SENTINEL FAILOVER, then I can't continue with the failover. */
if (!isleader && !(ri->flags & SRI_FORCE_FAILOVER)) {
mstime_t election_timeout = sentinel_election_timeout;
/* The election timeout is the MIN between SENTINEL_ELECTION_TIMEOUT
* and the configured failover timeout. */
if (election_timeout > ri->failover_timeout)
election_timeout = ri->failover_timeout;
/* Abort the failover if I'm not the leader after some time. */
if (mstime() - ri->failover_start_time > election_timeout) {
sentinelEvent(LL_WARNING,"-failover-abort-not-elected",ri,"%@");
sentinelAbortFailover(ri);
}
return;
}
sentinelEvent(LL_WARNING,"+elected-leader",ri,"%@");
if (sentinel.simfailure_flags & SENTINEL_SIMFAILURE_CRASH_AFTER_ELECTION)
sentinelSimFailureCrash();
ri->failover_state = SENTINEL_FAILOVER_STATE_SELECT_SLAVE;
ri->failover_state_change_time = mstime();
sentinelEvent(LL_WARNING,"+failover-state-select-slave",ri,"%@");
}자, 우리의 센티넬이 failover 실패를 선언한, 문제의 -failover-abort-not-elected를 떨어뜨린 메서드 코드입니다.
앞서 센티넬이 당시의 epoch에 1을 더한 값을 failover_epoch를 기록한다고 했죠.
이렇게 기록한 failover_epoch에 대해, 해당 에포크의 작업(failover)을 수행하기 위해 sentinelGetLeader()를 호출합니다.
/* Scan all the Sentinels attached to this master to check if there
* is a leader for the specified epoch.
*
* To be a leader for a given epoch, we should have the majority of
* the Sentinels we know (ever seen since the last SENTINEL RESET) that
* reported the same instance as leader for the same epoch. */
char *sentinelGetLeader(sentinelRedisInstance *master, uint64_t epoch) {
dict *counters;
dictIterator *di;
dictEntry *de;
unsigned int voters = 0, voters_quorum;
char *myvote;
char *winner = NULL;
uint64_t leader_epoch;
uint64_t max_votes = 0;
serverAssert(master->flags & (SRI_O_DOWN|SRI_FAILOVER_IN_PROGRESS));
counters = dictCreate(&leaderVotesDictType);
voters = dictSize(master->sentinels)+1; /* All the other sentinels and me.*/
/* Count other sentinels votes */
di = dictGetIterator(master->sentinels);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
if (ri->leader != NULL && ri->leader_epoch == sentinel.current_epoch)
sentinelLeaderIncr(counters,ri->leader);
}
dictReleaseIterator(di);
/* Check what's the winner. For the winner to win, it needs two conditions:
* 1) Absolute majority between voters (50% + 1).
* 2) And anyway at least master->quorum votes. */
di = dictGetIterator(counters);
while((de = dictNext(di)) != NULL) {
uint64_t votes = dictGetUnsignedIntegerVal(de);
if (votes > max_votes) {
max_votes = votes;
winner = dictGetKey(de);
}
}
dictReleaseIterator(di);
/* Count this Sentinel vote:
* if this Sentinel did not voted yet, either vote for the most
* common voted sentinel, or for itself if no vote exists at all. */
if (winner)
myvote = sentinelVoteLeader(master,epoch,winner,&leader_epoch);
else
myvote = sentinelVoteLeader(master,epoch,sentinel.myid,&leader_epoch);
if (myvote && leader_epoch == epoch) {
uint64_t votes = sentinelLeaderIncr(counters,myvote);
if (votes > max_votes) {
max_votes = votes;
winner = myvote;
}
}
voters_quorum = voters/2+1;
if (winner && (max_votes < voters_quorum || max_votes < master->quorum))
winner = NULL;
winner = winner ? sdsnew(winner) : NULL;
sdsfree(myvote);
dictRelease(counters);
return winner;
}
위의 sentinelGetLeader() 메서드를 통해 확인할 수 있듯이, 해당 failover_epoch의 leader 가 누군지(‘어떤 sentinel’ 인지) 그룹의 모든 센티넬에게 sentinelVoteLeader()를 요청하여 선출(vote)을 진행합니다.
이 때, 해당 에포크의 작업에 대해 합의하고, 수행할 leader의 선출에는 본인을 포함한 voters로부터 과반수 voters_quorum = voters/2 + 1; 이상 득표를 받아야 하는데요.

그러나, 시뮬레이션 상황에서 우리의 센티넬은 현재 3개 중 한 개가 남아 있죠.
이렇게 에포크에 과반 확보가 불가능한 sentinel은 election_timeout내에 failover 작업이 실패하게 되고,
결국 해당 Redis Relication은 master가 없는 상태로 남게 되는 것입니다.
번외: config rewrite
# Generated by CONFIG REWRITE
protected-mode no
user default on nopass ~* &* +@all
sentinel myid b1142c4bda42264da55c8c3487b1d97a2eca3c67
sentinel config-epoch sentinel_group 0
sentinel leader-epoch sentinel_group 1448
sentinel current-epoch 1448
sentinel known-replica sentinel_group <노드 2> 6379
sentinel known-replica sentinel_group <노드 3> 6379
sentinel known-sentinel sentinel_group <노드 1> 26379 7021e8b17a306e0f31edb9b098c842c4e303dd05
sentinel known-sentinel sentinel_group <노드 2> 26379 c365b2a2368389ef7c27ab2e2b45517b8ab3f9b7
Sentinel 3의 sentienl.conf 입니다.
sentinel이 failover를 계속해서 시도함으로써 epoch 또한 계속해서 단조 증가하게 되는데요.
이때, sentinel 프로세스의 현재 상태를 반영하기 위해(epoch의 증가) config-rewrite가 계속해서 수행됩니다.
failover가 정상적으로 이루어진다면 redis.conf 또한 config-rewrite가 수행됩니다. 이 케이스에서는 예외지만요.
며칠 만에 확인했더니 epoch가 어느새 1000을 넘었네요.
결론
Redis Sentinel의 quorum을 조정하였을 때, 분산 시스템 환경에서 발생할 수 있는 문제 상황을 시뮬레이션을 통해 알아보았습니다.
그 과정에서 Redis sentinel이 HA를 위한 Failover 수단으로서 Raft consensus 알고리즘을 사용함을 이야기했고,
결론적으로 Sentinel은 quorum의 조정에도 그룹의 과반이 존재해야 함을 확인했습니다.
REFERENCE
https://redis.io/docs/management/sentinel/
https://github.com/redis/redis/blob/unstable/src/sentinel.c
http://redisgate.jp/redis/sentinel/sentinel_election.php
데이터 중심 애플리케이션 설계, 마틴 클레프만 저, 위키북스
분산 시스템의 내결함성을 높이는 뗏목 합의 알고리즘(Raft Consensus Algorithm)과 정족수(Quorum) 개념 알아보기
'Redis' 카테고리의 다른 글
| Redis pub/sub vs. Kafka (0) | 2023.05.29 |
|---|---|
| Redis pub/sub (0) | 2023.05.29 |