
들어가며
영속성은 데이터베이스에 커밋된 쓰기 작업이 영구적으로 유지되도록 보장하는 데이터베이스 시스템의 중요한 속성입니다.
MongoDB 에서는 단일 멤버 인스턴스의 영속성을 넘어 클러스터(레플리카 셋) 수준의 영속성 또한 고려해야 하는데요.
이 문서를 통해 레플리카 셋의 영속성에 대해 정리해보도록 하겠습니다.
journal
단일 멤버 수준에서, 서버 오류 발생으로 데이터베이스가 다운되더라도 데이터 영속성은 보장되어야 합니다.
MongoDB는 데이터 영속성을 보장하기 위해 journal 저널 이라는 로그 선행 기입 write-ahead log(WAL)을 사용하는데요.
WAL은 데이터베이스 시스템의 영속성 보장을 위해 사용되는 일반적인 개념입니다.
WAL을 사용하면 데이터베이스 자체에 변경 사항을 적용하기 전, 영속성 있는 매체(즉, 디스크)에 변경 사항을 간단히 작성합니다.

MongoDB 4.0 부터 애플리케이션이 레플리카 셋에 쓰기를 수행하면, 모든 복제된 컬렉션의 데이터에 대해 MongoDB는 oplog 와 동일한 형식을 사용하는 journal entry 를 생성합니다.
MongoDB는 oplog를 통한 statement 기반 비동기 복제를 사용하는데요, oplog에 있는 명령문은 실제 MongoDB의 변경 사항을 대표합니다.
따라서 oplog 문은 버전, 하드웨어 등 레플리카 셋 멤버 간의 차이점과 관계 없이, 어느 레플리카 셋 멤버에든 적용 가능합니다.
또한 각각의 oplog 문은 멱등성을 가지고 있어, 데이터베이스는 항상 동일한 변경 사항을 가지게 됩니다.
대부분의 데이터베이스와 마찬가지로, MongoDB는 저널과 데이터베이스 데이터 파일의 in-memory view 를 가지고 있습니다.
기본적으로 저널 항목을 50밀리초마다 디스크로 플러시하고, 데이터베이스 파일을 60초마다 디스크로 플러시합니다.
데이터 파일을 플러시하는 60초 간격을 체크포인트 checkpoint 라고 하며, 저널은 마지막 체크포인트 이후 기록된 데이터의 영속성을 제공하는 데 사용됩니다.
필요에 따라 체크포인트는 커스텀이 가능하고, 디스크 I/O 의 빈도와 성능은 당연히 반비례하게 되겠습니다.
만약 쓰기 작업이 진행되는 도중 서버가 갑자기 중단되었다면 어떨까요. 데이터 영속성이 보장되지 않을 수 있겠죠.
MongoDB 는 서버가 재시작할 때 저널 파일을 읽어 올림으로써, 디스크에 플러시되지 않은 쓰기 작업을 다시 진행할 수 있습니다. (MySQL의 redo log와 역할이 같습니다. MySQL의 WAL이 바로 redo log)
Write Concern
쓰기 결과 확인 write concern 을 사용하면 애플리케이션이 쓰기 요청에 응답하는 데 필요한 승인 수준을 지정할 수 있습니다.
레플리카 셋 (혹은 샤드 클러스터)을 사용할 때 네트워크 파티션이나 서버 오류, 또는 데이터 센터 중단으로 인해 일부 멤버에 쓰기가 복제되지 않을 수 있습니다.
또한 비동기식 복제를 채택한 MongoDB는 복제 지연은 필연적인데요.
때문에 다음과 같은 상황이 발생할 수 있습니다.
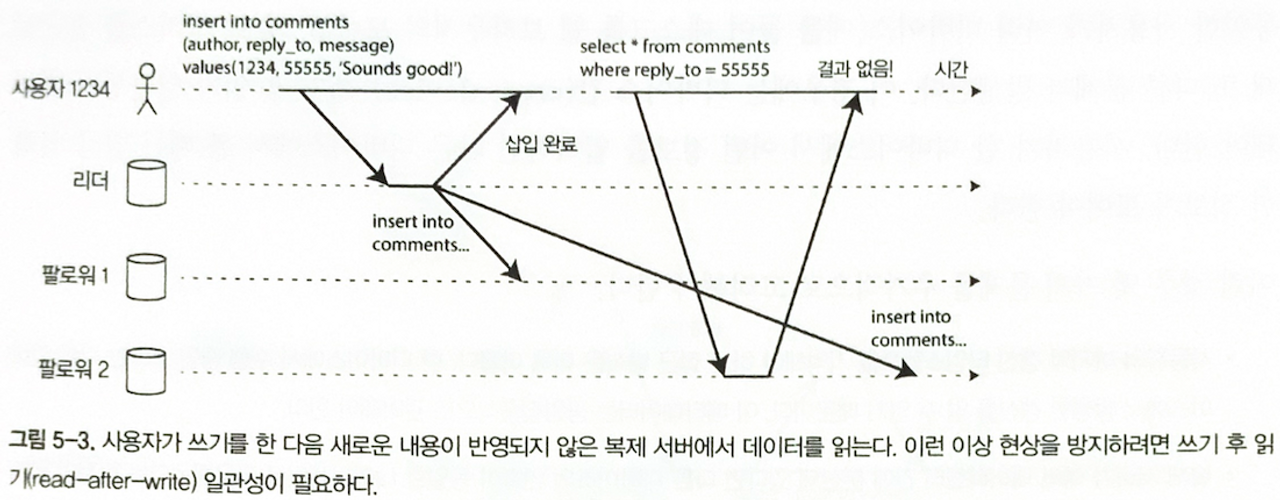
앞서 MongoDB replication을 구성할 때, read preference 에 대해 조금 이야기해보았습니다.
프라이머리에 변경사항(DML, CREATE, UPDATE, DELETE) 이 있었을 때, 세컨더리에 복제가 지연되어 따라잡지 못한다면? 쓰기 후 읽기 일관성이 보장되지 않을 수 있겠죠.
이렇게 복제가 지연되어 데이터 정합성이 맞지 않는 상황에서 프라이머리가 다운된다면? 세컨더리에는 변경된 데이터가 없어 데이터가 유실되는 상황이 발생할 수 있습니다.

이러한 문제를 조금이나마 방지하기 위해 MongoDB에서는 쓰기 결과 확인 write concern 기능을 제공합니다.
Primary와 Secondary(0 to ALL) 간의 Sync가 완료된 이후에, Client에게 데이터를 반환하여 클러스터 수준에서의 쓰기를 반동기식(semi-synchronous) 으로 적용하는 것입니다.
Write Concern Specification
write concern은 다음과 같은 필드를 포함할 수 있습니다.
{ w: <value>, j: <boolean>, wtimeout: <number> }
w Option
w Option을 통해 Replica set에 속한 멤버 중 지정된 수(value) 만큼의 멤버에게 데이터 쓰기가 완료되었는지 확인합니다.
프라이머리와 세컨더리를 합쳐 총 멤버 수가 5개인 Replica set 클러스터가 있다고 할까요.
이 경우 w : 5로 설정한다면 5개 이상의 멤버에 데이터 변경사항이 sync 되었을 때, 쓰기가 성공적으로 완료되었다고 응답합니다.
w: 3 이라면? 프라이머리 하나와 세컨더리 두 개, 총 3개의 멤버에 sync가 완료되었을 때 쓰기 성공을 응답합니다.
MongoDB 5.0 부터 w Option의 Default는 { w : “majority” } 가 되었습니다. (5.0 미만의 버전에서의 defulat는 { w : 1 })
셋 멤버의 과반에 쓰기 sync를 보장합니다. (예: PSS 아키텍쳐의 3개의 멤버라면, 3의 과반인 2개 멤버, 즉, Primary 1개와 Secondary 1개에 쓰기 보장)
w: 0 으로도 설정할 수 있는데요. 이 경우 쓰기 작업 요청을 승인하지 않습니다.
j Option
j Option 을 사용하여 저널링 수준에서의 쓰기 작업을 보장할 수 있습니다.
앞서 설명한 것과 같이 MongoDB는 변경 사항을 디스크에 기록하여 영속성을 갖추기 위해 journal 파일을 사용하는데요.
j Option을 true로 설정하여 MongoDB는 요청된 수 만큼의 멤버(w의 값)이 on disk 저널에 작업을 기록한 후에, 쓰기가 성공했다는 확인 응답을 클라이언트에게 전송합니다.
wtimeout
프라이머리에서 세컨더리로 데이터 동기화 시, timeout을 설정할 수 있습니다.
timeout 초과 시 error를 반환합니다. 설정 단위는 ms 입니다.
Read Concern
읽기 결과 확인 Read Concern 을 사용하면 레플리카 세트와 레플리카 세트 샤드로부터 읽은 데이터의 일관성과 격리 속성을 제어할 수 있습니다.
MongoDB 서버의 레플리케이션을 최종적 일관성을 갖춘 모델로 표현하기도 하지만, 데이터를 읽는 클라이언트 입장에서는 동기화(최신화) 되지 않은 데이터는 문제가 됩니다.
그래서 이런 동기화 과정 중에서 일관성 있는 데이터 읽기를 위해 Read Concern 옵션을 사용할 수 있습니다.
MongoDB 서버에서 데이터가 메모리에서만 변경됐든 저널 로그까지 기록됐든, 아니면 데이터 파일이 모두 디스크로 동기화됐든, 읽어가는 데이터에는 차이가 없어 단일 노드에서 읽는 데이터는 변수가 있을 수 없기 때문입니다.

이때 MongoDB 서버의 read concern 쿼리를 실행하면, MongoDB 서버는 모든 레플리카 셋으로 쿼리를 실행해서, 그 결과를 병합해서 반환하는 방식으로 오해할 수 있는데요.
그러나 실제로는 MongoDB read concern 은 오로지 레플리카 셋 멤버들의 Oplog 동기화 여부에만 의존하여, 쿼리의 read concern을 처리합니다.
위 그림에서와 같이 셋 멤버에게 Oplog 적용 여부를 확인하는 방식이 되겠습니다.
결론적으로 write concern 쓰기 결과 확인과 read concern 읽기 결과 확인을 효과적으로 사용하여, 데이터 일관성과 가용성 사이에서 trade off 할 수 있습니다.
예를 들어, 멤버 간 일관성 보장을 위해 레이턴시를 가겨가거나, 일관성을 낮추는 레이턴시를 줄일 수 있겠습니다.
Read Concern Levels
다음과 같은 읽기 결과 확인 레벨이 가능합니다:
| level | Description |
| local | Replica set에 대한 읽기가 정상적으로 수행되었는지 여부를 판단하지 않고 그대로 데이터를 반환 |
| available | 기본적으로 local과 기능은 동일하지만, 샤딩 된 클러스터에 대한 읽기 작업인 경우 사용 |
| majority | 다중 문서 트랜잭션을 제외한 읽기 작업에 한해, 과반수의 Replica set 멤버가 데이터를 읽는 것을 허용함을 보장 |
| linearizable | 선형화. Replica set에 쓰기 작업이 끝날때 까지 기다리고 난 후 읽기 데이터 반환 |
| snapshot | 특정 시점에 mongod 인스턴스에 있는 데이터 전체 복사본 |
local
쿼리가 실행되는 MongoDB 서버가 가진 최신의 데이터를 반환하는 방식으로 작동합니다.
MongoDB 서버의 Default read concern 옵션입니다. 최신 데이터를 프라이머리 멤버만 가진 상태에서, 프라이머리가 비정상적으로 종료되거나 네트워크 파티션이 발생하면 데이터가 롤백되어 Phantom Read 와 비슷한 상황이 발생할 수 있습니다.
availability
기본적으로 local 과 같은 기능을 가집니다. 데이터가 롤백 될 수 있습니다.
샤딩된 클러스터에서 “available” read concern 은 가능한 가장 짧은 지연시간을 제공하지만, 동기화되지 않아 정합성을 잃은 데이터를 반환할 수 있습니다.
majority
레플리카 셋에서 다수의 멤버들이 최신의 데이터를 가졌을 때만 읽기 결과를 반환합니다.
다수의 멤버가 가진 데이터에서쿼리 결과가 반환되므로 클라이언트가 읽었던 데이터가 롤백으로 인해 사라질 가능성은 매우 낮지만, 일부 레플리카 셋의 멤버가 동시에 연결할 수 없는 상태가 되면 여전히 Phantom Read 가 발생할 수 있습니다.
linearizable
읽기 데이터를 반환 전에 Replica set에 쓰기 작업이 진행중이면, 해당 작업이 끝날 때 까지 대기 후 결과를 반환합니다. majority는 쓰기 작업과 관계 없이 데이터를 반환하지만, liearizable의 경우 쓰기 작업이 끝날 때 까지 대기하므로 상대적으로 성능이 느립니다.
snapshot
특정 시점에 mongod 인스턴스에 있는 데이터의 전체 복사본입니다.
인과적 일관성을 갖춘 트랜잭션인 경우, 트랜잭션이 “majority”로 커밋될 때 트랜잭션 작업은 트랜잭션 시작 직전의 작업과 인과적 일관성을 제공하는 과반수 커밋된 데이터 스냅샷에서만 읽도록 보장합니다.
일과적 일관성을 갖추지 않은 트랜잭션의 경우, 트랜잭션이 “majority”로 커밋될 때 트랜잭션 작업은 과반수 커밋된 데이터 스냅샷에서 읽도록 보장합니다.
결론
MongoDB가 영속성을 제공하고 클러스터 수준에서 데이터 일관성과 정합성을 갖추는 방법에 대해 알아보았습니다.
MongoDB는 단일 인스턴스 수준에서 영속성 보장을 위해 journal 파일을 디스크에 기록합니다.
Replica set 수준에서 Oplog 를 통한 statement 기반 비동기 복제로 발생할 수 있는 데이터 일관성, 정합성 문제를 해결하기 위해 쓰기 시에는 write concern, 읽기 시에는 read concern 을 사용하여 성능과 데이터 정합성 사이에서 trade off 할 수 있습니다.
'mongoDB' 카테고리의 다른 글
| MongoDB Replica set에 majority 미만의 멤버가 available한 경우 (0) | 2023.05.28 |
|---|